Why evals matter
A successful AI analyst is a reliable AI analyst. To measure and improve reliability, Bag of words provides Evals — lightweight tests you can run against your agent and data sources any time. Evals set a repeatable benchmark for your AI analyst and make continuous development safe as context evolves (instructions, tables, definitions) or models change.Run evals regularly to set a standard for your AI analyst and catch regressions as you update instructions, modify tables, edit context, or switch LLMs.
Deterministic checks vs. Judge checks
Bag of words supports two complementary evaluation styles:- Deterministic tests (Create Data rules): Strict, machine-checkable assertions like “used tables contain
customerandpayment”, “row count is greater than 0”, or “generated code is valid SQL”. These are great to prevent regressions and ensure required sources/columns are used. - Judge tests (LLM Judge): Natural-language scoring using a small model that reads the full agent trace and decides Pass/Fail from a rubric. Perfect for presentation, UX and reasoning behaviors that aren’t easily captured by strict rules (e.g., “should produce a bar chart and explain groupings clearly”).
Viewing all tests
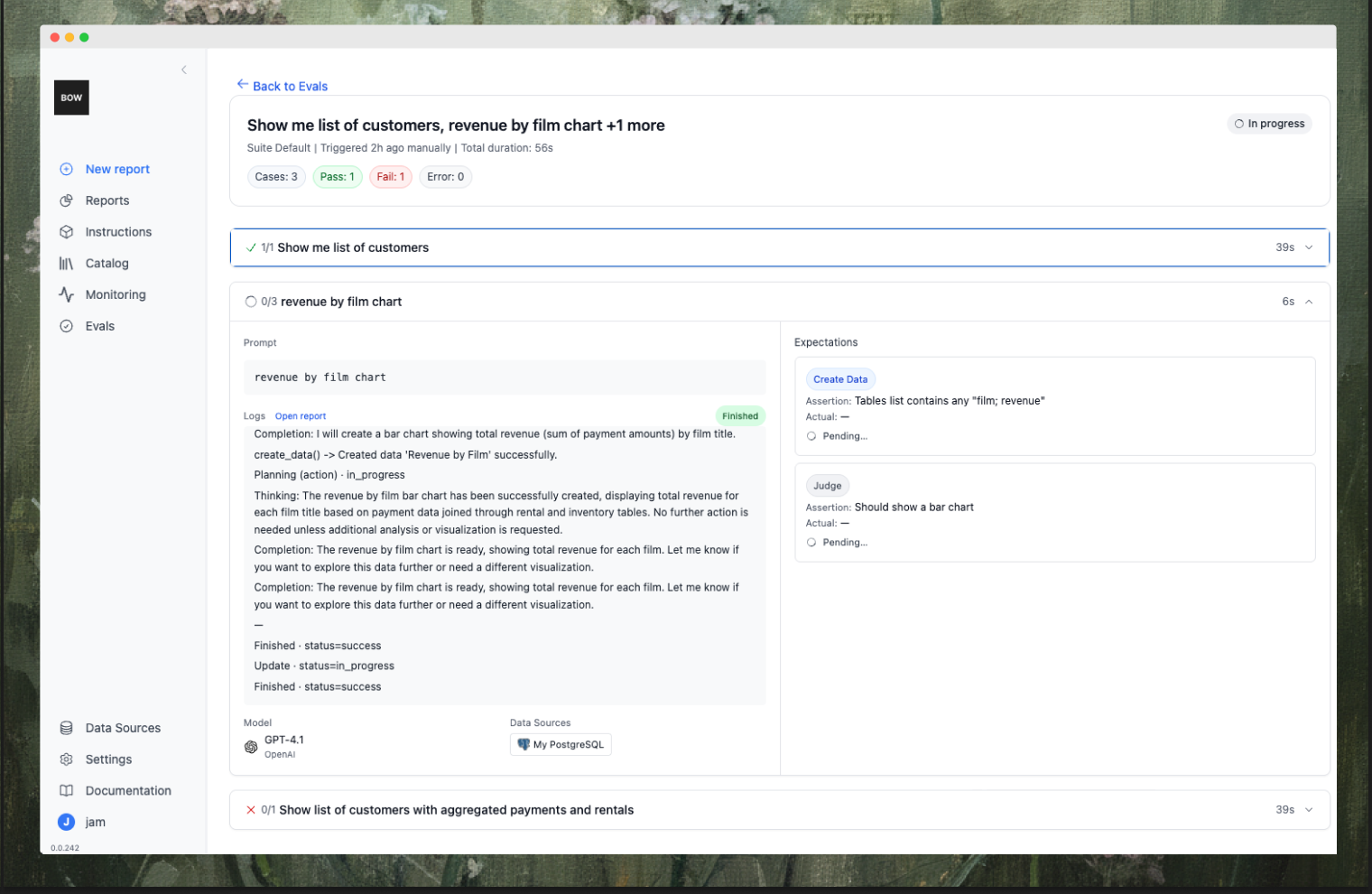
The Evals page lists all test cases, their suites, rules attached, and last run status. Select multiple tests and run them together, or open one to review results and logs.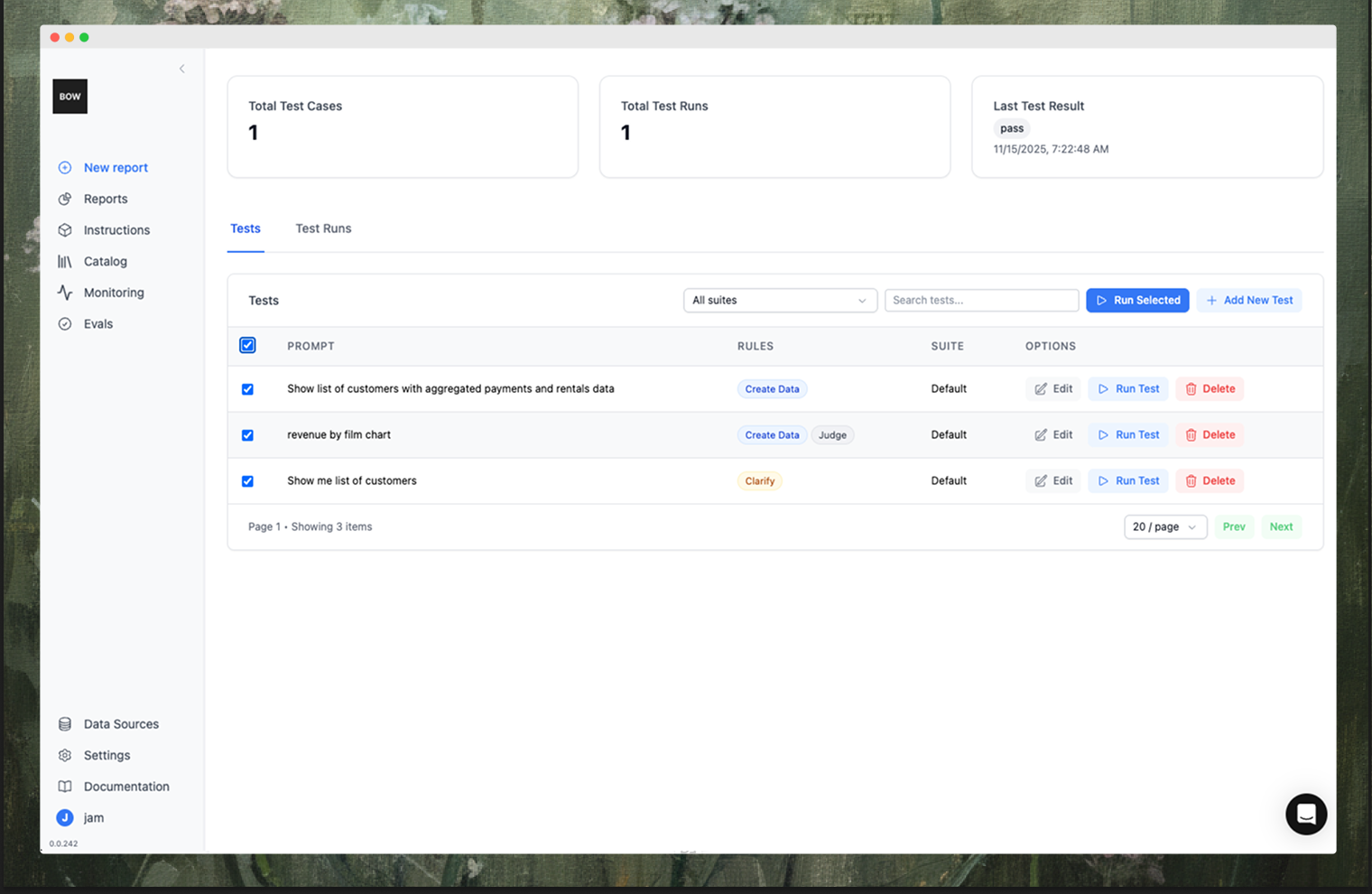
Creating a test
Click Add New Test to define a test case.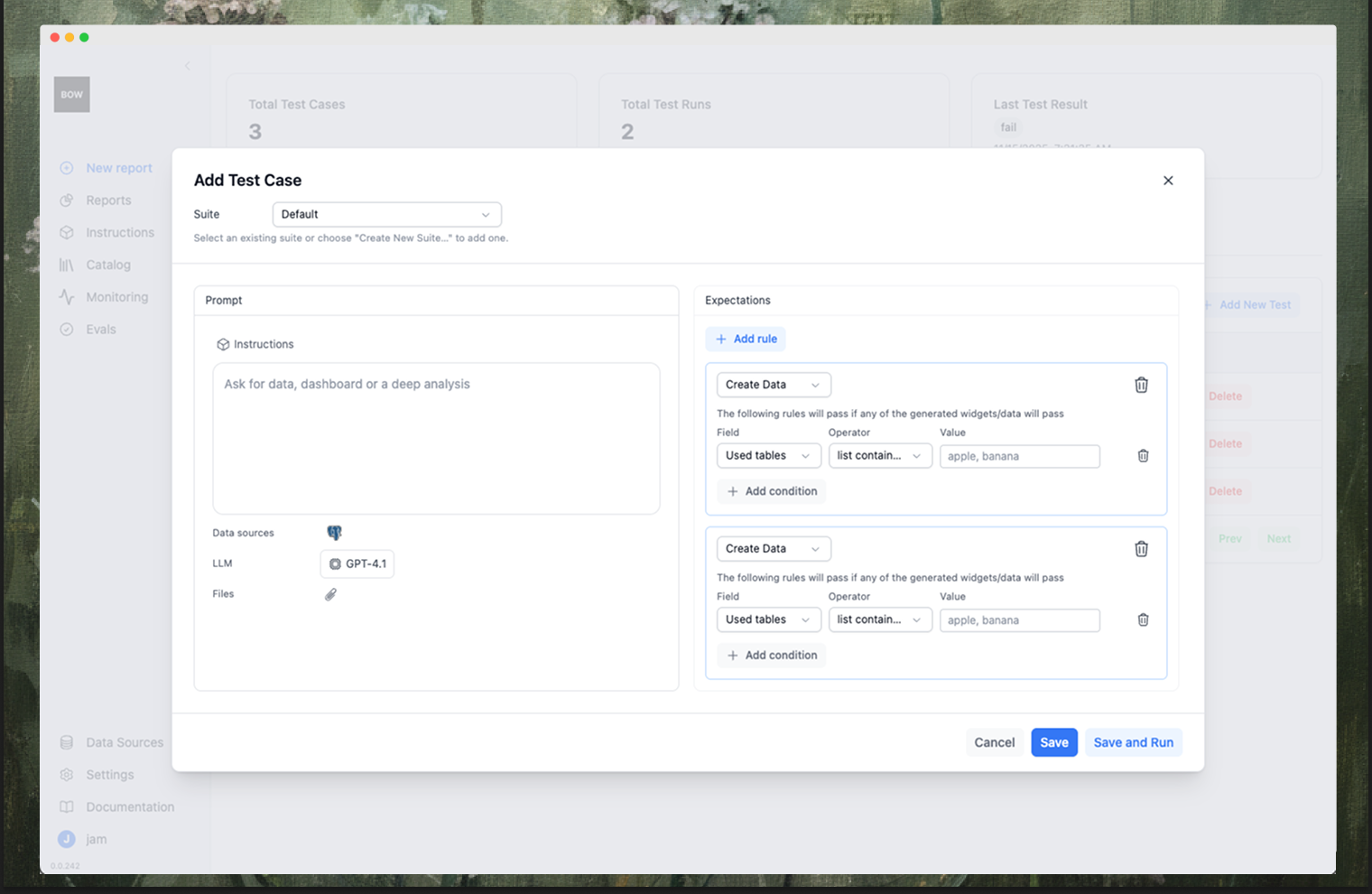
Prompt and Expectations
- Prompt: What a user would ask the AI analyst, e.g., “revenue by film chart”.
- Data sources & LLM: Choose which connected data and model to use for this test.
- Files (optional): Attach files the agent can reference for this run.
- Expectations: One or more rules that determine Pass/Fail. A test passes if any “Create Data” rule passes or if the Judge outputs Pass (depending on your rule set).
Expectation types
-
Create Data (deterministic)
Machine-checkable assertions against the result and trace of generated data and widgets. Add one or more conditions:
- Used tables: list contains any/all of
[customer, payment] - Used columns: list contains required columns
- Row count: equals / greater than / less than N
- Generated code: exists / is valid / matches dialect
customerandpaymenttables: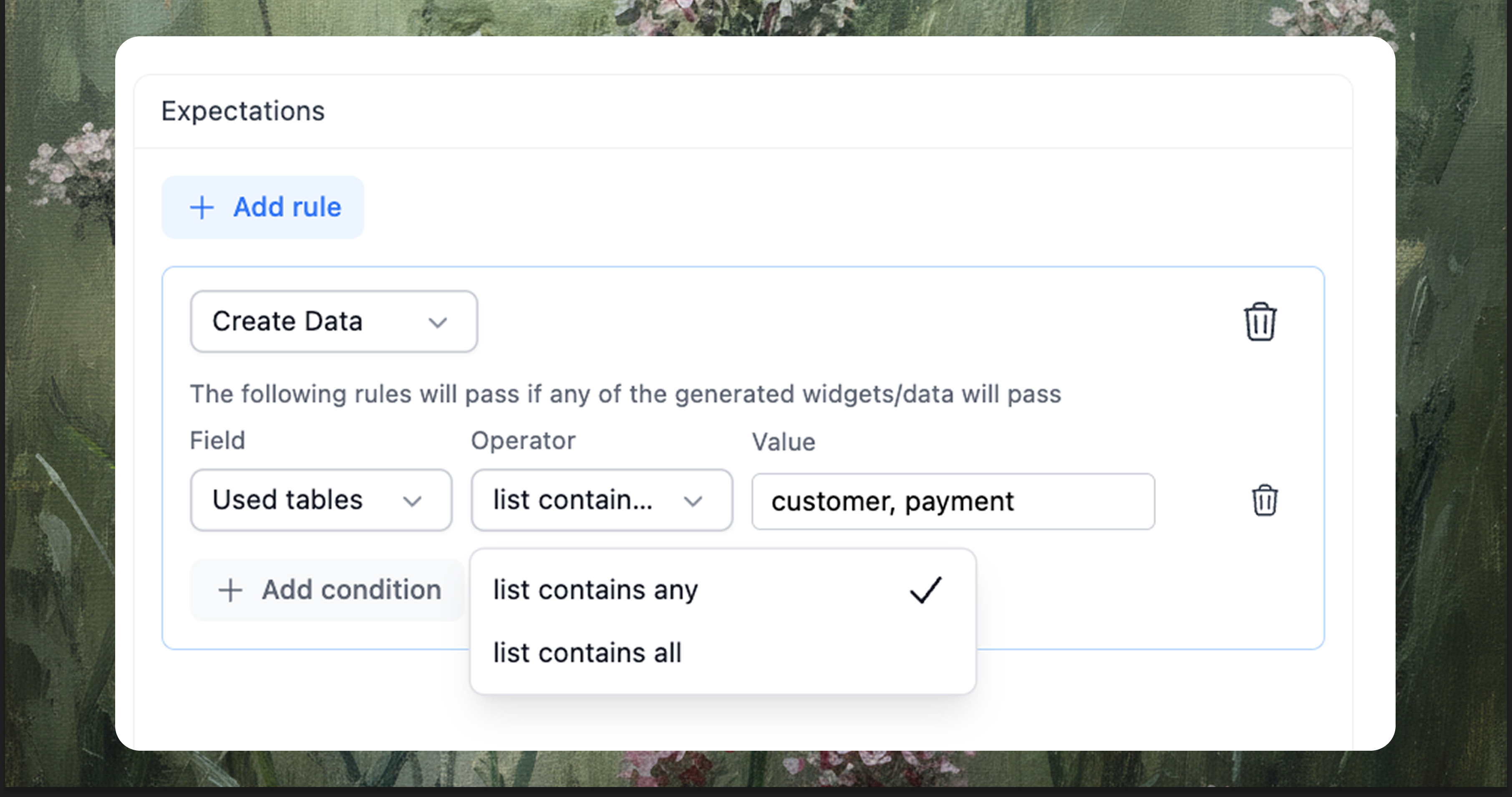
- Used tables: list contains any/all of
- Clarify Requires the agent to ask a clarifying question before proceeding. Use this when you expect responsible behavior in ambiguous cases (e.g., financial data with missing filters).
-
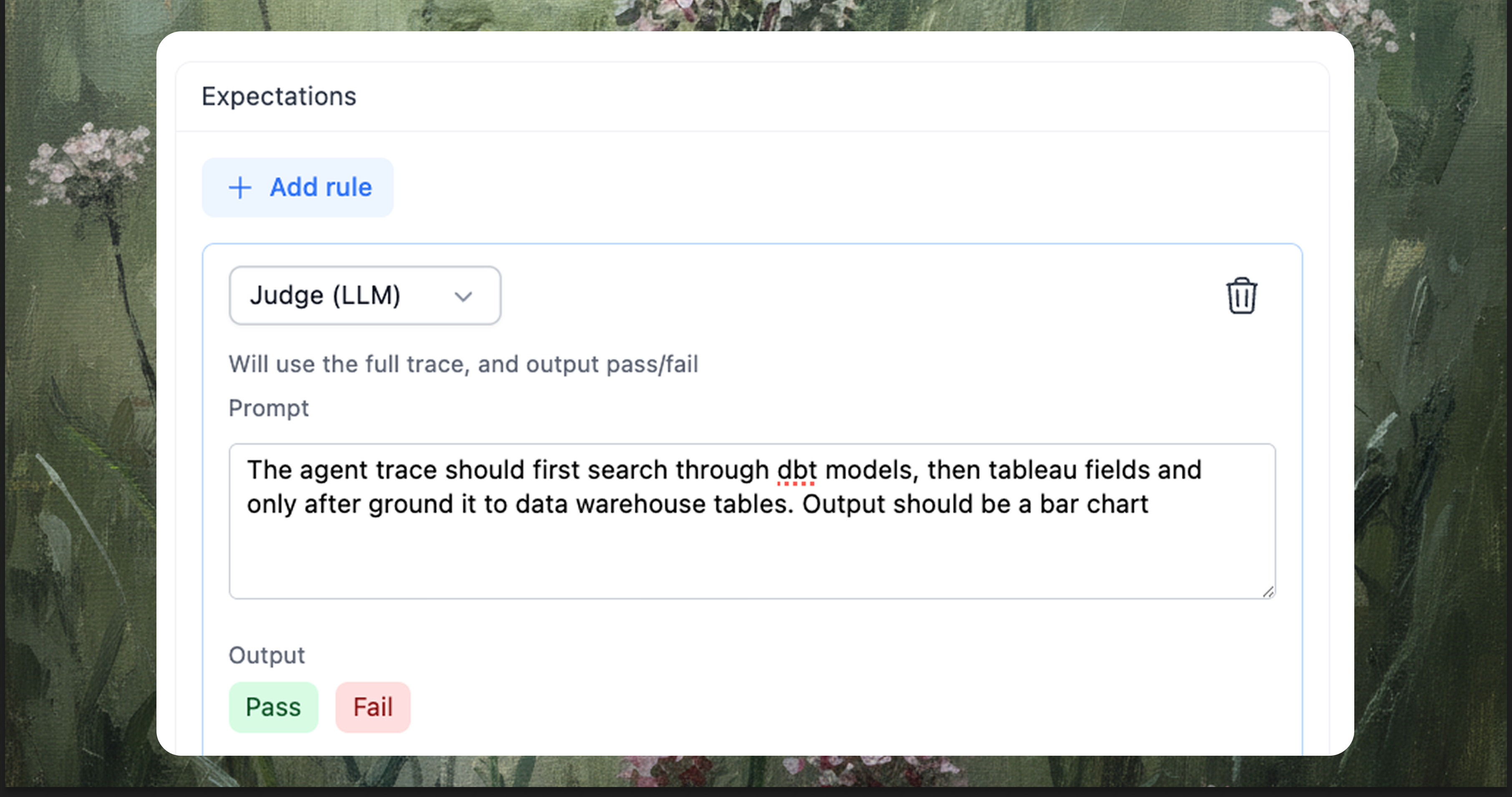
Judge (LLM)
A lightweight evaluator model reads the full trace and applies your rubric. Provide a plain-English prompt and mark output Pass/Fail. Useful for visualization expectations, narrative quality, or workflow steps.
Test suites
Group related tests into a Suite (e.g., “Default”, “Finance”, “Marketing”). Suites make it easy to run focused subsets during iteration or CI.Running a test and reading results
- From the Evals list, click Run Test (single) or Run Selected (batch).
- Open a run to review:
- Logs: step-by-step planning, tool calls, completions
- Expectations: each rule’s assertion, actuals, and pass/fail
- Artifacts: generated code, data preview, and visualization
Best practices
- Start with deterministic core checks: ensure critical tables/columns are used and rows are sane.
- Layer in a judge rubric for agentic workflow, UX and reasoning goals (visual types, clarity, documentation links).
- Keep prompts realistic: mirror how your users actually ask.
- Evolve alongside context: when instructions, schemas, or context change, update tests to lock in new expectations.