Overview
Even the best models or agentic systems will fail without the right context. If the system doesn’t know what active users means in your organization, it cannot produce the right result. That’s why context is a first-class concept in Bag of words: every Agent run begins by constructing a context block that contains definitions, rules, and prior learnings. Bag of words includes features for creating, managing, and monitoring context and context performance, including support for complex data structures. For best results, data teams should ensure that context coverage is thorough and use the available tools to track and improve context quality.What goes into context
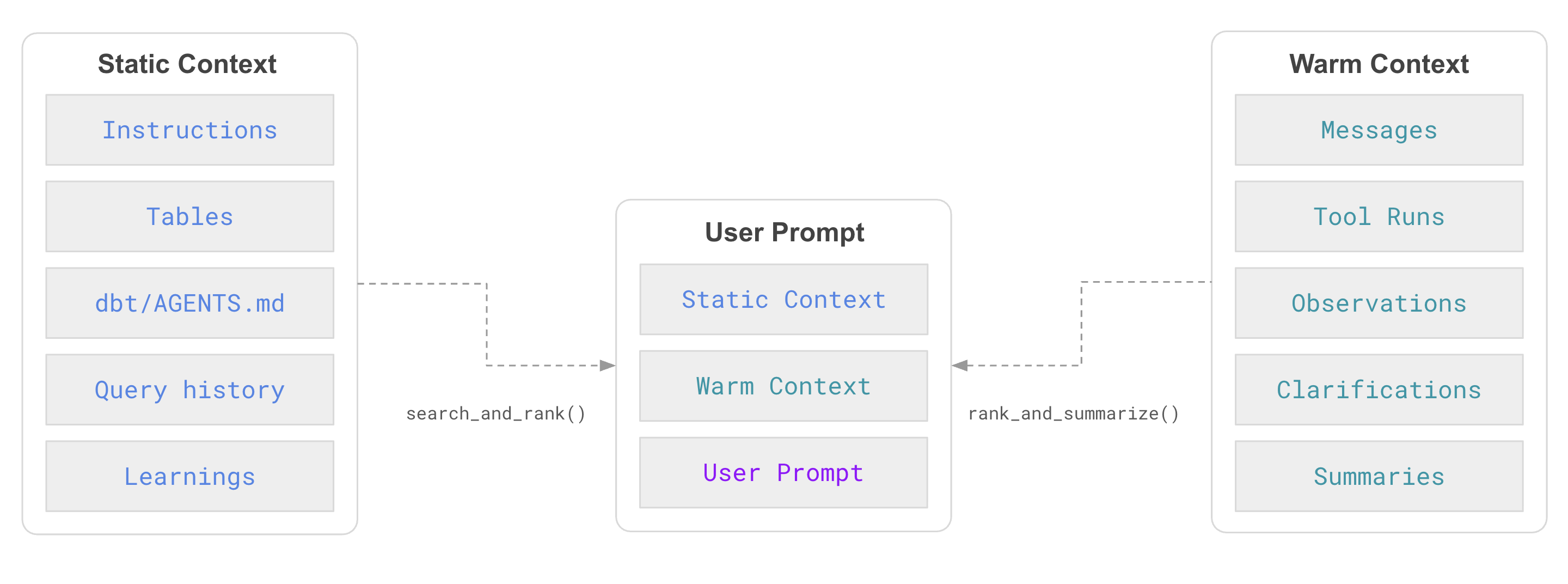
Static context
Static context is the foundation: information that rarely changes and encodes the organization’s definitions. It is loaded at the start of each run.- Instructions — scoped rules and guardrails such as KPI definitions, preferred joins, exclusions, or conventions (e.g., “use fiscal calendar,” “exclude PII columns”).
- Schemas & tables — metadata describing sources, tables, columns, relationships, and types.
- dbt/LookML, Git repos, Agents.md — canonical definitions of metrics, joins, and code that encode business logic.
- Learnings — knowledge accumulated across runs: query history, user feedback, validation outcomes, lineage down to the table/column level.
Warm context
Warm context is transient and grows throughout a single Agent run. It captures everything the system learns or produces while satisfying the request.- Previous messages — the conversation history for the request.
- Tool calls — queries, dashboards, and their intermediate results.
- Clarifications — user inputs captured when the Agent asks for missing info.
- Observations — errors, validation outcomes, and reflections from the loop.