Overview
The Agent is the core execution engine in Bag of words. Its purpose is simple: take a natural-language request, the organization context, enrich —> and return reliable results—queries, reports, or dashboards—that a team can actually use. In data, reliability is critical. A wrong join or misapplied metric isn’t just noise; it can drive the wrong decisions. That’s why the Agent is built around a loop that emphasizes validation, iteration, and context-awareness. The goal is not just to get “an answer,” but to know when the system is confident, when it’s uncertain, and to make that process observable. This makes it more robust than naive text-to-SQL: instead of a single guess, the Agent reasons, retries, validates, and uses context until it produces results that are consistent and explainable.The Agent Loop
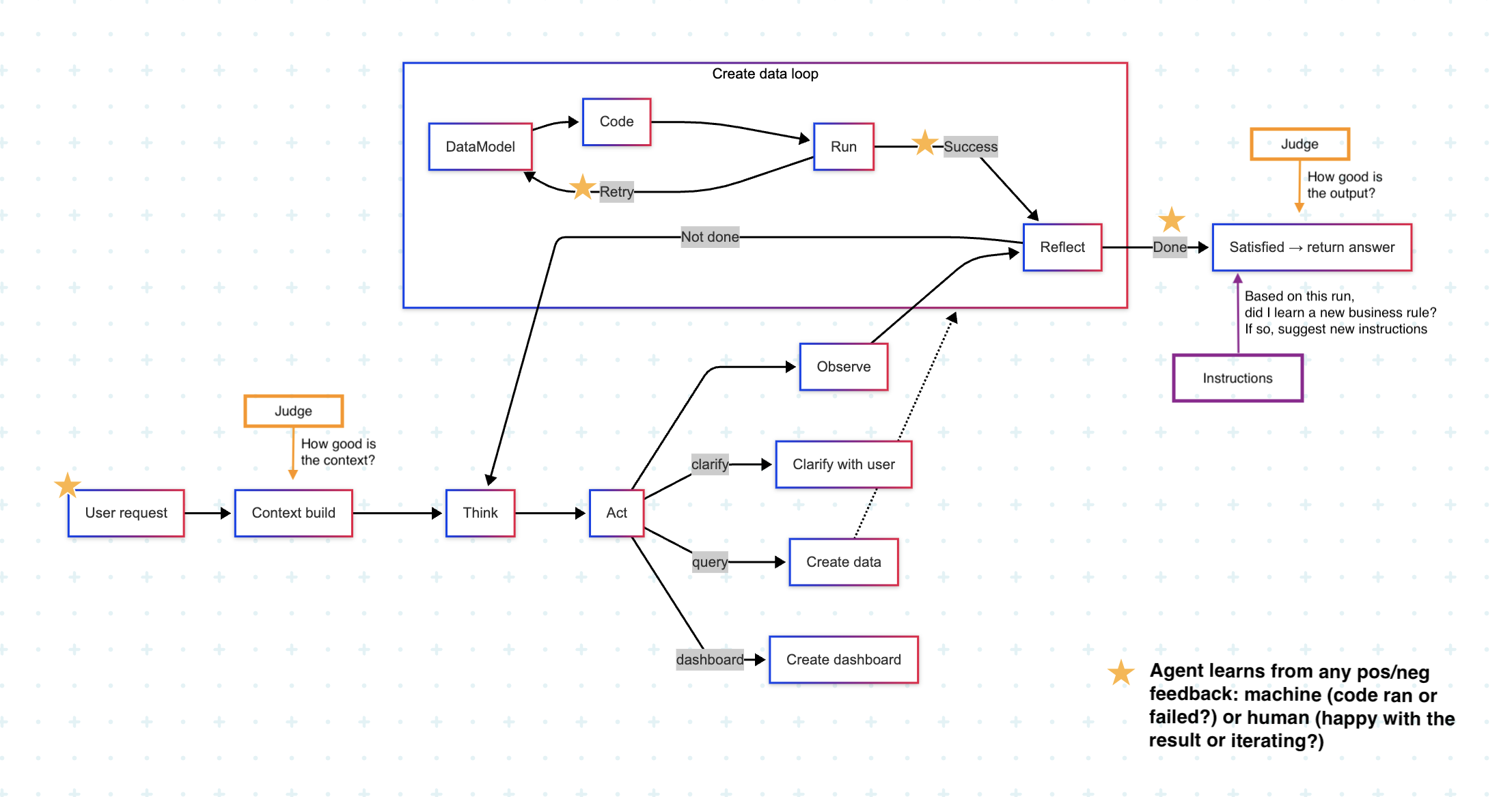
- Think — plan the next step.
- Act — pick an action: search context, clarify with the user, create a query, assemble a dashboard.
- Observe — capture outputs (results, schema info, errors, validation outcomes).
- Reflect — decide whether the request is satisfied or whether another step is needed.
Nested loops for queries
Query generation is handled as an inner loop:- Model — propose tables, joins, grain, filters; check against definitions.
- Code — emit SQL/Python; dry-run/EXPLAIN; inspect types/row counts.
- Reflect/repair — revise model or code; ask the user if ambiguity blocks progress.
Learning from feedback
- The system captures all available feedback and learnings. This includes cases where a user is dissatisfied and continues to iterate, as well as outcomes such as code that fails to execute, code that runs successfully, code that runs successfully but does not align with the data model, and many other scenarios.
- The system has an optional Judge (recommended) that scores context, instructions, and results for each agent run. This significnalty improves the system and makes it easier for admins to control the agent
- At the end of each agent run, if the system identifies a new rule, term — whether mentioned by the user or learned throughout the analysis, the system will suggest new instructions to improve the performance of the system and make it more relevant for the organization
Why this matters
This design supports both simple aggregations and multi-step analysis or root-cause investigations. It’s built to:- Validate instead of assuming first attempts are correct.
- Expose reasoning and errors so teams can inspect the process.
- Recognize known-unknowns and ask instead of guessing.
- Capture learnings and judge feedback so future runs become more reliable.
Tools & Configs
The agent is tool based, with tools crafted and designed specifically for the data analysis work. They range from creating queries and visualizations, to clarifying user prompts, designing dashboards, and more Everything is tracked in the platform, and you can see how the agent made decision in each agent run. And there’s also an aggregated view of the tools use throughout the executed runs Some of the agent configurations are customizable:- LLM see data
- Limit analysis steps
- Limit code retries
- LLM Judge
- Validate Code/Data Model
- Suggest Instructions