> ## Documentation Index
> Fetch the complete documentation index at: https://docs.bagofwords.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Monitoring
> Track accuracy, context quality, and agent behavior across your AI data layer
## Overview
To maintain a reliable AI data analysis layer, monitoring is not optional—it’s core. Bag of Words provides deep monitoring and diagnostic tools that track how agents, context, and instructions perform over time.
From high-level accuracy and effectiveness scores to detailed traces of individual runs, you can move between **aggregate trends** and **drill-down inspections**. This ensures you know not only whether the system is working, but *why*—and where it needs adjustment.
The monitoring suite covers:
* **Accuracy & quality** of results across queries and reports
* **Context performance**, including instruction effectiveness
* **User feedback** capture and loop-through
* **Agent activity**: what tools were triggered, how loops evolved
* **Successful vs. failed queries**, tied back to schema and lineage
* **Lineage grounding**, tracing metrics and queries all the way down to the table/column level
## Key Metrics
* **Accuracy** — Percentage of queries returning correct or acceptable results.
* **Instruction Effectiveness** — How well instructions influenced the outcome (scored automatically per prompt).
* **Query & Message Volume** — Track adoption and usage across teams.
* **User Feedback** — Direct human signal to reinforce or correct agent behavior.
These aggregated metrics help spot trends, regressions, and opportunities for improving reliability.
## Drill-Down Diagnostics
For each agent run, admins can:
* Inspect the **context block** that was used, including instructions, schema, and lineage.
* See which **tools/actions** were triggered (create query, clarify, search context, etc.).
* Track **step-by-step reasoning**, observations, and reflections.
* Evaluate **failed queries**, with clear error categories (execution error, missing context, invalid data).
This lets you not only see that accuracy dipped, but *why*—and whether it’s a data issue, instruction gap, or model misstep.
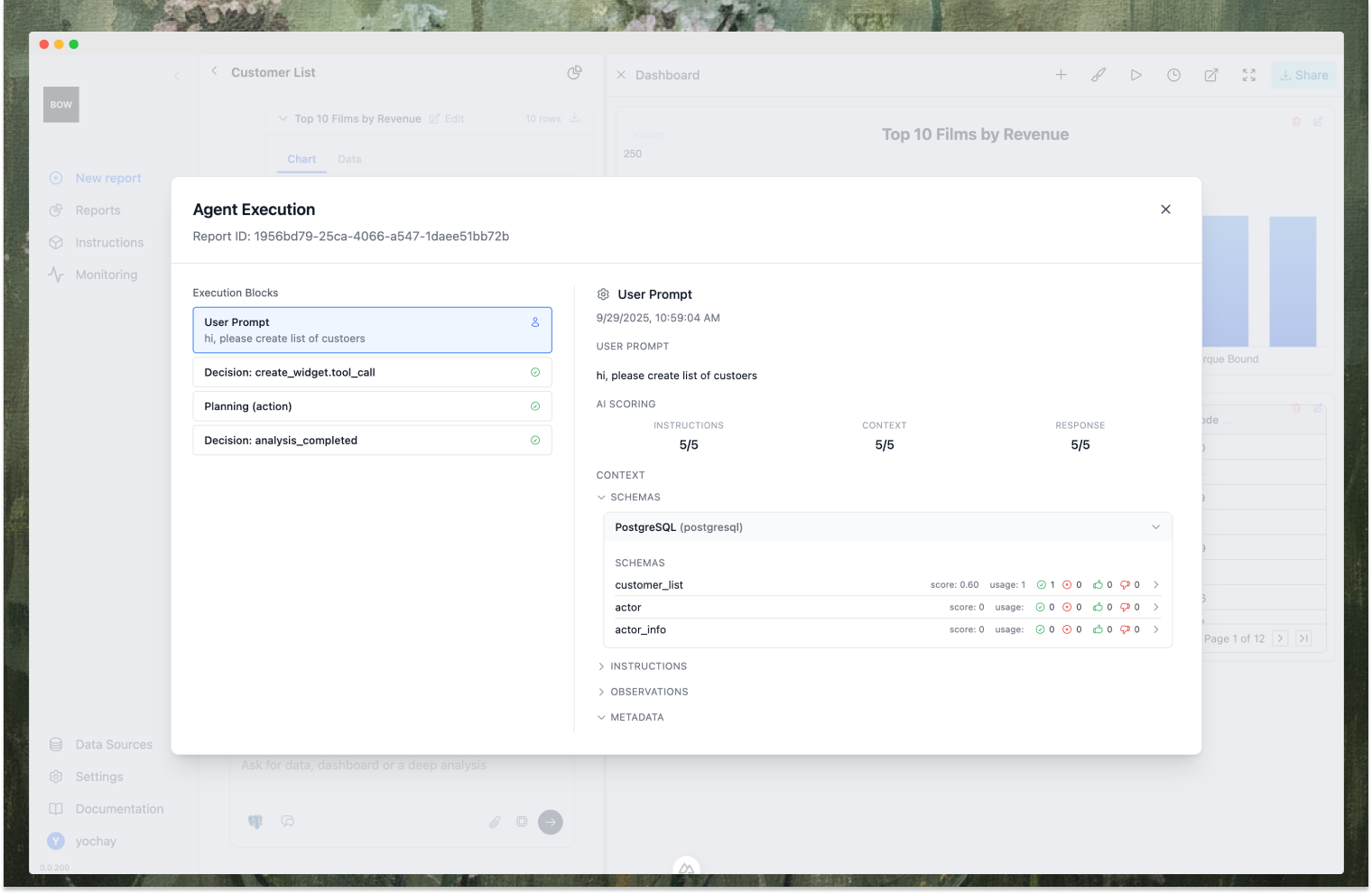 ## Lineage & Root Cause
Every query is tied back to table- and column-level lineage. If an agent produces the wrong result, you can see *which* schema element, join, or definition was at fault. This grounding is critical for enterprise trust: no black boxes, only explainable paths.
## Why this matters
Monitoring ensures the AI data layer is not a “set and forget” system. It gives teams the ability to:
* Validate and **continuously improve context** (instructions, definitions, lineage).
* **Detect regressions early**, before they impact decisions.
* Attribute errors to the right cause (model, context, or data).
* Provide **governance and accountability** across the org.
In short: monitoring makes the system observable and controllable—so it can be trusted.
## Lineage & Root Cause
Every query is tied back to table- and column-level lineage. If an agent produces the wrong result, you can see *which* schema element, join, or definition was at fault. This grounding is critical for enterprise trust: no black boxes, only explainable paths.
## Why this matters
Monitoring ensures the AI data layer is not a “set and forget” system. It gives teams the ability to:
* Validate and **continuously improve context** (instructions, definitions, lineage).
* **Detect regressions early**, before they impact decisions.
* Attribute errors to the right cause (model, context, or data).
* Provide **governance and accountability** across the org.
In short: monitoring makes the system observable and controllable—so it can be trusted.